Benchmarking Customer Service LLMs: Exploring Intercom's Switch from OpenAI to Anthropic
In this post we explore in detail Intercom's switch from OpenAI to Anthropic
case_studycomparisonanthropicopen_ai
Oct 30, 2024

Earlier this month, in a pivotal shift that signals the evolving landscape of AI, Intercom bet big on Anthropic, replacing OpenAI in their newly launched Fin 2 chatbot. Fin 2 is powered by Anthropic’s Claude 3.5 Sonnet, a big change as the original Fin was powered by GPT4.
An obvious question would be “how big of an impact could they expect to see in the quality of their product?”. We can’t know exactly the system Intercom has worked to build, so when they say “With Claude, Fin answers more questions, more accurately, with more depth, and more speed”, we don’t have real technical context on that impact, from the outside. Focusing on accuracy, can we find a way to empirically compare the models they likely used (either GPT-4o or GPT-4o-mini) to the model they’ve moved to (Claude Sonnet 3.5)? These tests were conducted prior to the Oct 22nd update of Claude 3.5 Sonnet and represent the information Intercom had available to them to make their change.
Evaluating models
To compare the potential performance of models many teams go on vibes, having ad-hoc conversations or using one or two ‘eval’ questions and ‘feeling’ good or bad about the model, prompt and configuration they have chosen. We’ve been thinking about the problem a little differently. For any task, we want to prove that a model is both suitable and reliable. To show both we need data, not vibes, at a scale that proves what we see isn’t a fluke.
As a first attempt at evaluating the models, we might get hard data by testing them on a classification task. For example, we can use a small dataset of 400 emails (synthesised for this test, available on HuggingFace), known to be either genuine or phishing, and see if each LLM can correctly identify them. Doing this, we find Claude 3.5 Sonnet achieved 85% accuracy, which was the same as a locally-run Llama3.1-7B, lower than the GPT-4o score of 87.5% and GPT-4o-mini, which scored 86.25%. So is Claude worse? Well, the result is a reliable indication of the model setup, but this is not a suitable test of a customer support agent. LLMs are extremely flexible tools, but good performance on one task is not a guarantee of good performance on another.
A Task Like Fin
In order to go deeper understanding what these models are good at, it might be tempting to look at academic question-answering benchmarks as ‘roughly equivalent’. Unfortunately, there is a world of difference between those questions (e.g. knowing the capital of France) and helping a customer change their password. We should really test these models on a task like the sort of support work a customer support agent does.
Backtesting
If we had Intercom’s historic data we could use previous questions to give an indication of model performance, a process called backtesting. This is a powerful tool for comparing algorithms, used frequently by traders to ask “would I have made more money with a different trading strategy last month?”. With a history of LLM use we would have a ready-made dataset to use, we could ask “What would my product have looked like last month if we used Claude rather than GPT-4o?” and directly, concretely compare their performance at scale, to show reliable metrics, a sort of integration test that would then give you the measurable impact of any AI change you make. We can replay a scenario in different models to build data and not just vibes.
Building a dataset
Since we don’t have access to Fin’s systems or data, we need to synthesise something similar to the sorts of prompts Fin would feed a model. We will go into detail on this process in an upcoming post about data synthesis for testing, the script we used to generate the data can be found here. At a high level, we invert the process used by a Retrieval-Augmented Generation system to build prompts that a customer support agent would use. Taking a section of a support doc and asking an LLM to take on the persona of a user and ask a question answered by the doc. These are the easiest sort of questions for a customer support agent to answer, but they begin to represent the task. Our dataset is 1,000 of these prompts, including question and support doc, and we will get each model to answer every question.
Results
Our backtesting approach makes it easy to see the quantitative, aggregate data that summarises key strengths and weaknesses of each model on the task (shown above), as well as dive into individual generations, to see the qualitative performance of each model on a single example, much like an eval. The readability of answers from all candidates is roughly the same, all producing high-school-level text, though Claude is very slightly in sophomore rather than freshman territory. That increased complexity coupled with longer answers might be an advantage for Claude. Again, the task dictates what is truly important, so let’s take a look at some of the signals we are seeing in detail.
Response Length
Claude responses are generally the longest of our three candidates, about 11 words more than GPT-4o on average, or 5 more than GPT-4o-mini. Is this what Intercom means by ‘deeper’? Let’s look at a specific example, both Claude and GPT-4o answering the same exact question:
I’ve been trying to set up Fin AI Agent in our Messenger, but I’m getting some conflicts with an existing Workflow. Can you help me understand how to use the ‘Let Fin answer’ step to avoid this conflict? Specifically, what happens when a customer opens a new conversation and clicks on a reply button - does that mean Fin will never fire if the composer is disabled at the start of the Workflow?
In the answers compared below, Claude is more wordy certainly, but we can see its output is more clear and explanatory, which Intercom would be right to classify as “deeper” in the context of a chatbot. Qualitatively this reads like a stronger response. Interestingly, when we dig in, we see GPT-4o offered incorrect information, “When a customer opens a new conversation and clicks on a reply button, they enter the Workflow, and Fin AI Agent will not trigger.” is not true, and Claude offered correct information.
Sentiment
On average Claude shows more emotion, whether joy, sadness, anger or fear. The difference is quite small, but we should be aware of the fact that presentation and sentiment can have a huge impact on customer experience. Let’s look at the response that had the strongest fear sentiment detected:
“Hey, I’m trying to create a Custom Action in my Workflow, but I have no idea what endpoint to call on our third party support tool API. The thing is, we just use some generic API for our email support and the guy who set it up last year left the company… Can you walk me through this ‘Select Custom Action’ step again? What do I need to provide here?”
What’s interesting here is that it’s clear the emotion is mild in all three responses, Claude likely registers as the most fearful seemingly because it is mirroring the customer’s annoyance back to them (“I want to reassure you that it’s completely normal to feel unsure about API details, especially if the person who set it up is no longer with the company. We can work through this together!”). Also notice that Claude goes in-depth on the steps required, and GPT-4o would require more information.
LLM-as-Judge
One way the success of Fin is judged is by ‘resolutions’, whether it solved the customer’s problem. We don’t have access to real data on this, like corresponding support tickets with closed/open statuses, which can be used to further directly measure success. Instead we can use a common technique, LLM-as-judge, as a proxy. This is an accepted evaluation technique that uses an LLM to provide a qualitative judgement as a large scale test of a sample of the answers generated by these models
We used Llama 3 7B to judge each model’s response to 100 samples from our dataset. In the LLM’s judgement both GPT-4o and Claude Sonnet 3.5 were judged to have not resolved two questions, with GPT-4o resolving 98 and Claude resolving 96. Interestingly GPT-4o-mini resolved the most, with 99 resolved. As we’ve seen GPT-4o-mini tends to be more direct, with less commentary, a more “just the facts” approach.
Claude wrote two responses that weren’t labelled as either resolving or not resolving, one of which looks like this:
The LLM was instructed to give a quality rating to each response, and here we find what may be one of the main reasons Intercom have chosen to go with Claude as opposed to GPT-4o. As shown below, there are fewer unhelpful responses from Claude than GPT-4o, which may be a good baseline to build from, with better failures than GPT-4o. In short, the bad experience with Claude isn’t as bad as the bad experience with GPT-4o, which is hugely important over millions of support conversations. A rising tide of improving quality on average, rather than focusing on a better experience for the high end.
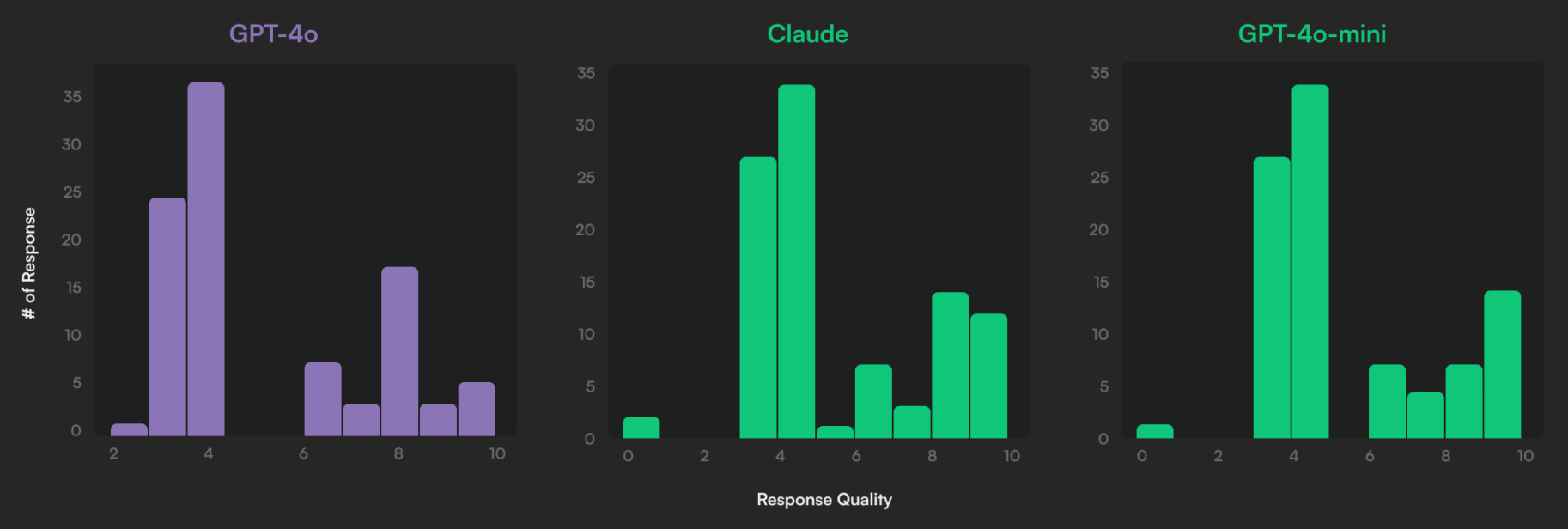
Conclusion
The data reveals nuanced findings: Claude offers significant advantages for complex interactions, though it’s not universally superior to GPT-4o. Intercom’s switch makes strategic sense given Claude’s ability to improve their most challenging support cases.
Our testing here is only the start; a framework that provides valuable baseline comparisons. It’s crucial to note that Intercom’s team are likely spending a lot of time on testing and improving their implementation. Their ML team can optimize prompts, enhance document retrieval, and fine-tune system components to amplify Claude’s strengths.
The key lesson? Model selection alone isn’t enough - success requires deep understanding of each model’s behaviors and limitations. As the AI landscape evolves, the ability to conduct representative testing will be crucial for teams to make data-driven decisions and iterate effectively. At Reva, we are working to build out tooling and expertise that helps teams, whether big or small, measure and improve their AI performance, and you can find out more about us here.